14 Days of JINA AI Challenge - Featurepreneur


I am a sophomore aiming to understand the concepts and applications of Jina AI through Featurethon season 3 an event conducted by Featurepreneur. I have utilised Learning Analytics to track my progress throughout this learning voyage.
DAY 0 : Orientation - 24/10
An orientation was held through Zoom meetings to introduce the challenge and it's goals by Raja Sir and the Featureprenuer Team. A brief intro on where to get started and how was given.
Time spent : 1.5 hours
#Featurepreneur #Featurethon #Jina
DAY 1 : Understanding Neural Search and Role of JINA AI - 25/10
In the first day of the learning challenge, I went through what is neural search and how it revolutionises the searching process, it's cool features and the problems one has to handle when creating it. The most important part of it was learning how Jina AI could help solve those issues.
Source of learning : JINA AI Documentation
Time spent : 1.5 hours
#Featurepreneur #Featurethon #Jina
DAY 2 : Installation and Basics of JINA AI - 26/10
Today, I began completed the installation of JINA AI using conda and surfaced through the different components of JINA AI.
Guide for installation : JINA AI Installation
Note: It is a good practice to create a new environment for JINA AI specifically.
Time spent : 2.5 hr
#Featurepreneur #Featurethon #Jina
DAY 3 : Basic Components in JINA AI - 27/10
I delve into the basic components in JINA AI. There are basically three of them which govern the working of JINA AI.
- Document - it deals with all the datatypes provided.
- Executor - it is used to execute the Document the way we want.
- Flow - it is like a pipeline to direct which is to be executed when.
Time spent : 1.5 hours
#Featurepreneur #Featurethon #Jina
DAY 4 : Data Collection - 28/10
I worked on collecting data for the project which gave me an opportunity to explore webscrapping. I used selenium for the process and it was extremely satisfying though!! Today, there was a significant progress in the learning journey and I hope to make more.
Selenium documentation : Click Here
Time spent : 2 hours
#Featurepreneur #Featurethon #Jina
DAY 5 : Document in JINA AI - 29/10
Today I learnt about the Document in Jina AI. Documents are basically datatypes in Jina. You can have any of the following type.
- URI - link to local files like file path or URL.
- Blob - for images, videos, audios and 3D Mesh.
- text - the general text content in files.
- content - it is also text based but shorter like..
d = Document(content = "Hello World") - tags - these are like dictionary with key-value pairs.
I also worked upon many more functions and concepts associated with Documents like chunks and matches.
To learn more about Document : Click Here
Time spent : 2.5 hours
#Featurepreneur #Featurethon #Jina
DAY 6 : DocumentArray in JINA AI - 30/10
Today I learnt about the DocumentArray in Jina AI. DocumentArray is a list of Documents. You can do the following operations with it.
- Construct
- Delete
- Insert
- Sort
- Filter
- Traverse
Declaration:
da = DocumentArray[ Document( text = " hello")]
There were also contents related to iterating through the DocumentArray. The concepts of chunks, granularity, adjacency and matches were understood in much detail than yesterday.
Documentation link : DocumentArray
Time spent : 3 hours
#Featurepreneur #Featurethon #Jina
DAY 7 : DocumentArrayMemmap in JINA AI - 31/10
DocumentArrayMemmap is what I was working upon. It has similar function to that of DocumentArray , ie, saving Documents as a list. The advantage of using it is it occupies less memory. The characteristics of DocumentArrayMemmap are:
- Stores Documents directly on the disk.
- Keeps small lookup table in memory.
- A buffer pool of Documents with fixed size.
- Memory-loaded documents are kept in the buffer pool to allow modifying documents.
Creation and Adding of Documents to the DocumentArrayMemmap
from jina import Document, DocumentArrayMemmap
d1 = Document( text = "Hello" )
d2 = Document( text = " World!!" )
da = DocumentArrayMemmap( './my-memmap' )
da.extend([d1,d2])
I also learnt about other functions related to DocumentArrayMemmap which can be found in the documentation linked. With this, I completed the understanding of the first component Document.
Time spent : 2.5 hours
#Featurepreneur #Featurethon #Jina
DAY 8 : Executor in JINA AI - 01/11
With the beginning of the new month, I began to understand about the next component in the list - Executor. Basically, it is the processing component in JINA AI.
Key points to remember:
- Every user made executor is a subclass of
jina.Executor. It must inherit it. - The methods in the executor created must be decorated with
@requestsif it must be considered byFlow( third component). - Endpoints ( eg: on = '\hello' ) can be specified along with the decorator if it needs to map a specific input.
- If endpoints or not specified in becomes a default handler for all endpoints.
Tip: Executor and Flow are inter-related so in order to either one, you have to have a basic understanding about the working of both components.
Code snippet for executor :
from jina import Executor, Flow, Document, requests
class MyExec ( Executor ):
# request with endpoint
@requests ( on = '/index' )
def function( self, **kwargs ):
print( " Hello world ")
#request without endpoint
@requests
def func( self, **kwargs ):
print( "flow ")
f = Flow().add( uses = MyExec )
with f:
#it accesses the first function
f.post( on ='/index', inputs = Documents(text = " welcome "))
#it access the default handler
f.post( on = '/leaf', inputs = Document())
To learn More about Executor : Documentation link
There are other concepts that you need to know to understand the working of executors in depth. I shall add links to it here.
Time Spent : 3 hours
#Featurepreneur #Featurethon #Jina
DAY 9: Executor Continued in JINA AI - 02/11
We can also write the program as an extern module in the Executor and use it via YAML. That is what I saw today, there are types of writing code one is Inline and separate module
- Why use a Separate module is that when you have multiple Python files you can all insides a special folder (call it
executor) and put__init__.pyfile inside it.. ├── config.yml └── executor ├── demo.py ├── __init__.py └── dataset.py
Time spent : 2 hrs
####Featurethon ####Featurepreneur ####Jina
DAY 10: Flow in JINA AI - 03/11
I entered the last component in the Jina AI that's Flow. Flow creates a pipeline for Documents and is processed by the Executors.
We can override Executor with
metaswithrequests
code snippet for predecessors via needs
from jina import Flow
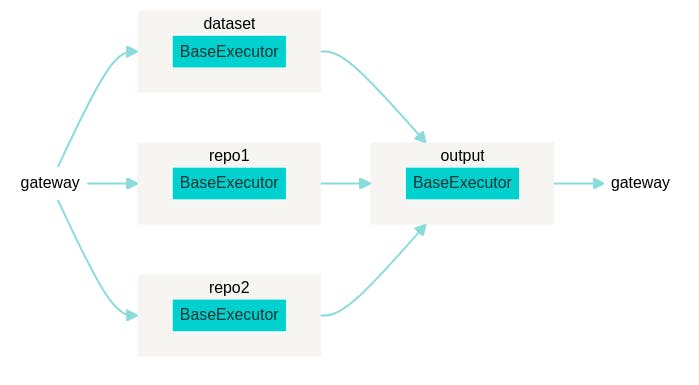
f = (Flow()
.add(name='repo1', needs='gateway')
.add(name='repo2', needs='gateway')
.add(name='dataset', needs='gateway')
.needs(['repo1', 'repo2', 'dataset'], name='output'))
f.plot()
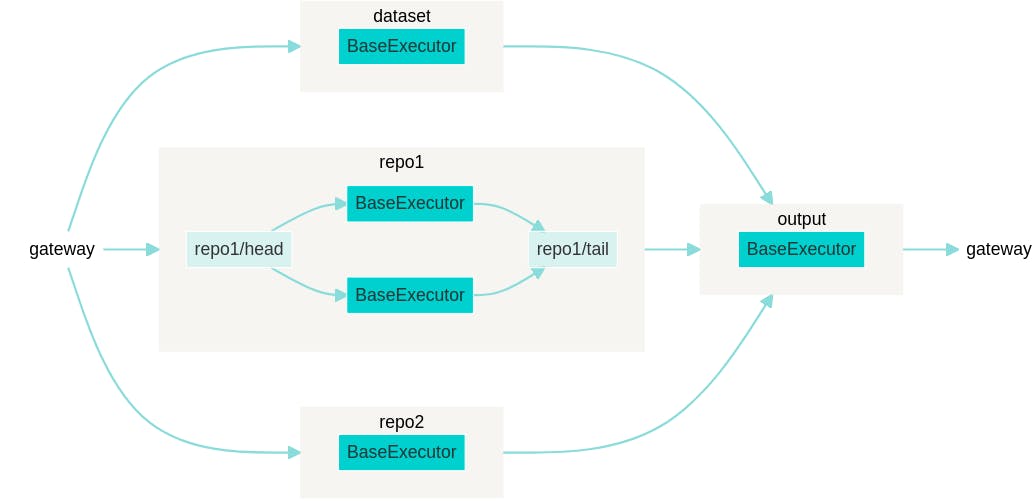
Scale Executor uses Replicas: to mean creating multiple copies of the same Executor and passing to only one replica of the Executor
from jina import Flow f = (Flow() .add(name='repo1', replicas= 2) .add(name='repo2', needs='gateway') .add(name='dataset', needs='gateway') .needs(['repo1', 'repo2', 'dataset'], name='output')) f.plot()
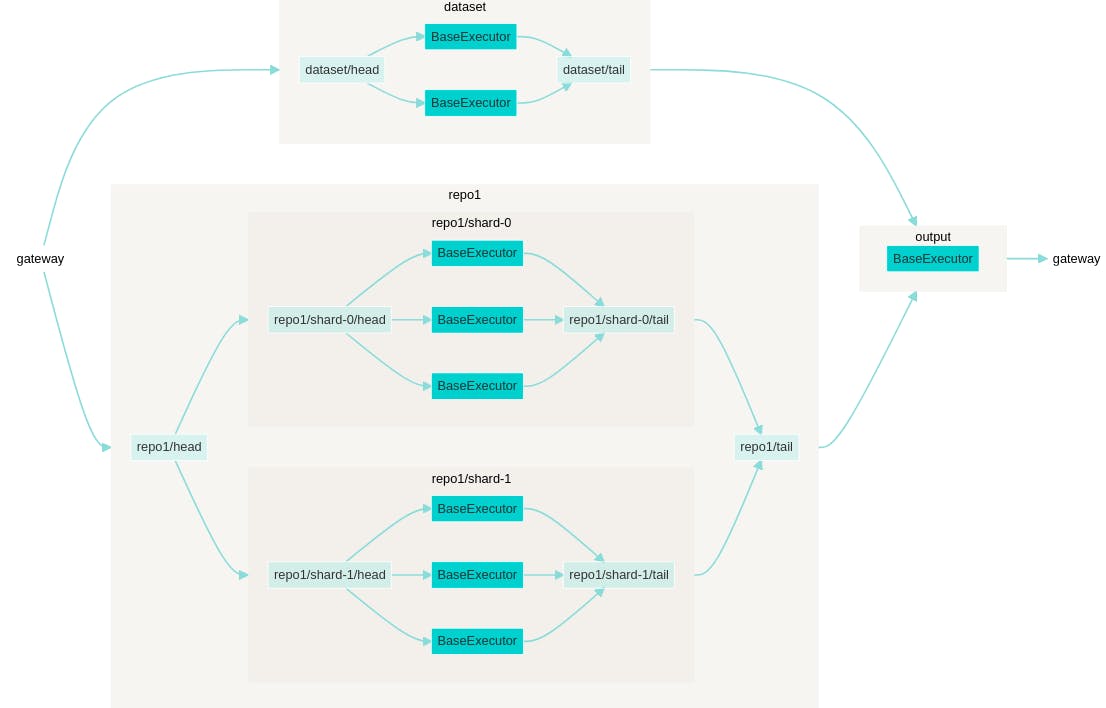
Using Shards: means partitioning data into several parts which enable the distribution of data across multiple machines. This helps in:
- Decreases the latency.
When the full data doesn't fit on one machine.
from jina import Flow f = (Flow() .add(name='repo1',shards=2, replicas= 3) .add(name='dataset', replicas= 2,needs='gateway') .needs(['repo1', 'dataset'], name='output')) f.plot()
Source:
Time spent: 3 hrs
#Featurepreneur #Featurethon #Jina
DAY 11: Streamlit - 04/11
I started with learning Streamlit and trying to go through the components and go through the videos on that.
Installation command :
pip install streamlit
How to run Streamlit file?
streamlit run filename.py
 You can use the Streamlit as a frontend for the ML and DataScience which is easy and customisable.
You can use the Streamlit as a frontend for the ML and DataScience which is easy and customisable.
Source:
Time spent: 1:30 hrs
#Featurepreneur #Featurethon #Jina
DAY 12: Working with code - 05/11
Today is the day for us to work on the most important thing that was the backend and we were trying to integrate code.
We try to combine the code with the NumPy and Pandas libraries.
Currently, we are facing errors and we are fighting to fix them.
Time spent: 3 hrs
#Featurethon #Featurepreneur #Jina
DAY 13: Working with code - 06/11 - Final Day
It was literally race against time but we completed the project !! It was a fun voyage as hoped at the start. Turning back, I can say that I am confident to say that I know JINA AI. I extend my sincere thanks to Featurepreneur team for organising Featurepreneur season 3. It lead me into a new forum in AI. And yes.. I would highly recommend you guys to begin learning JINA AI.
Time spent: 3 hrs
#Featurethon #Featurepreneur #Jina